文章信息:
题目:TorchEEGEMO:基于脑电图的情绪识别深度学习工具箱
期刊:Expert Systems with Applications
环境:pytorch = 1.11.0 CUDA = 11.3
摘要:
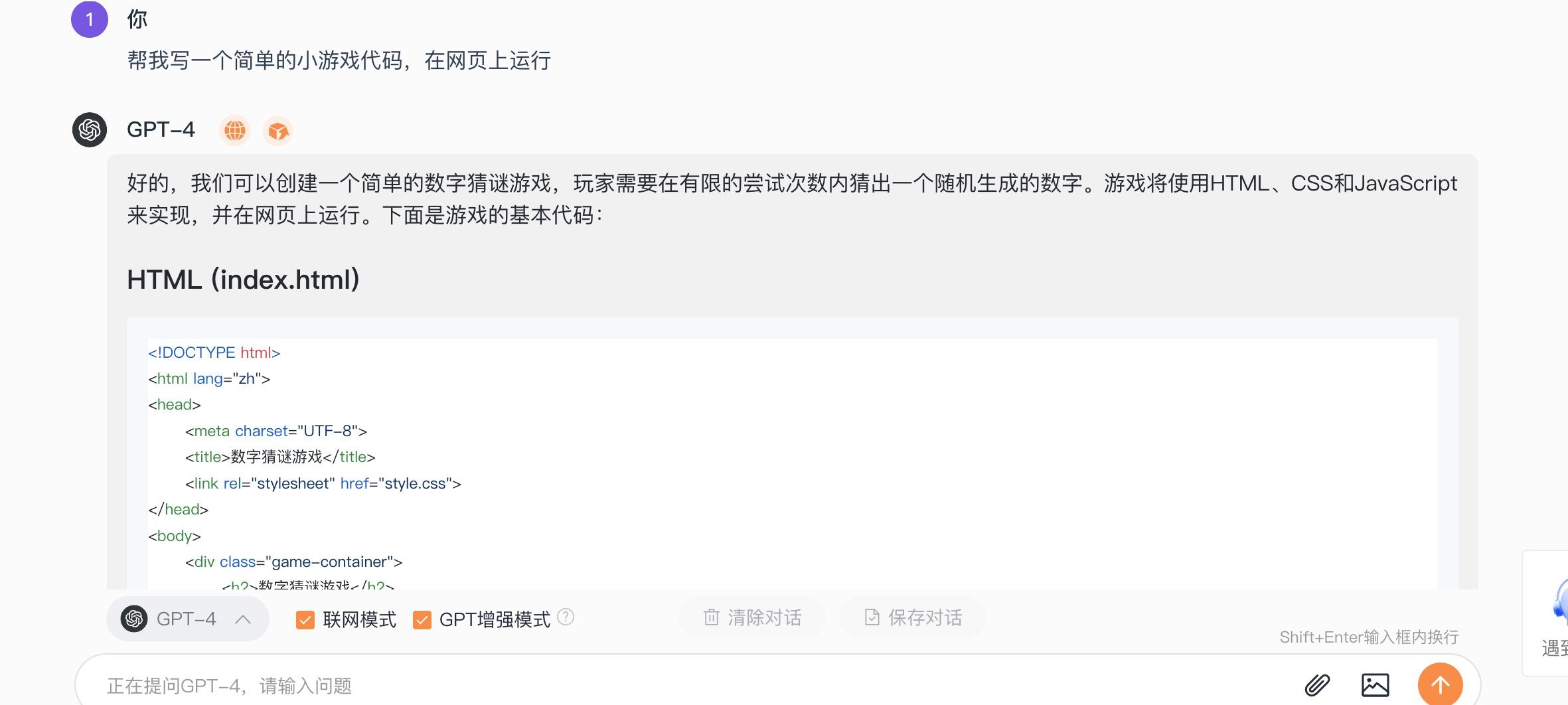
一个python工具箱TorchEEG,将工作流程分为五个模块:datasets、transforms、model_selection、models、trainners。每个模块都包含即插即用函数,用于构建和管理工作流程中的某个阶段。鉴于对感兴趣时间窗口的频繁访问,我们引入了一个以窗口为中心的并行输入/输出系统,以增强深度学习系统的效率。
(一)Introduction
贡献:
1.首次提出基于脑电图的情感识别深度学习工具;
2.将深度学习工作流程分为五个模块:datasets、transforms、model_selection、models、trainners。并且这些模块采用了最先进的算法。
3.引入了一种新的方式来组织脑电数据的时间窗口,即以窗口为中心的输入/输出系统。这种设计允许对感兴趣的窗口进行高效索引,并利用缓存的预处理结果,解决了深度学习系统效率的瓶颈。
(二)Related work
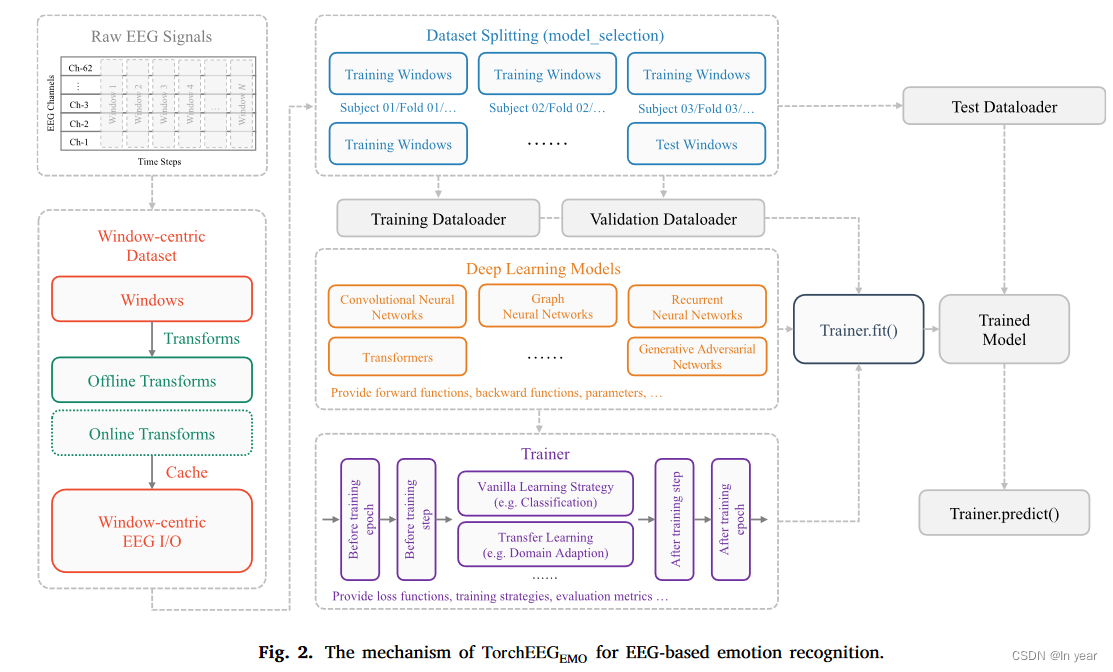
1.输入原始脑电信号后,首先应用datasets模块将原始脑电信号分块成时间窗口;这些窗口经过数据预处理,并使用transforms模块中的transformers进行特征提取;将结果缓存在以窗口为中心的EEG I/O模块中。
2.model_selection根据窗口的元信息(例如试验索引、会话索引或主体索引)将窗口划分为训练、验证和测试集。
3.models模块提供各种深度学习模型,例如卷积神经网络、图神经网络等。这些模型和数据集可以被馈送到训练器中以优化模型。
4.训练步骤包括:用损失函数计算和优化算法的内置方法,以实现不同的训练策略,例如域自适应。通过调用fit函数,模型被优化。
5.训练好的模型然后可以通过predict函数在测试样本和应用场景中的脑电信号样本上进行预测。
(三)The overall framework of TorchEEG EMO
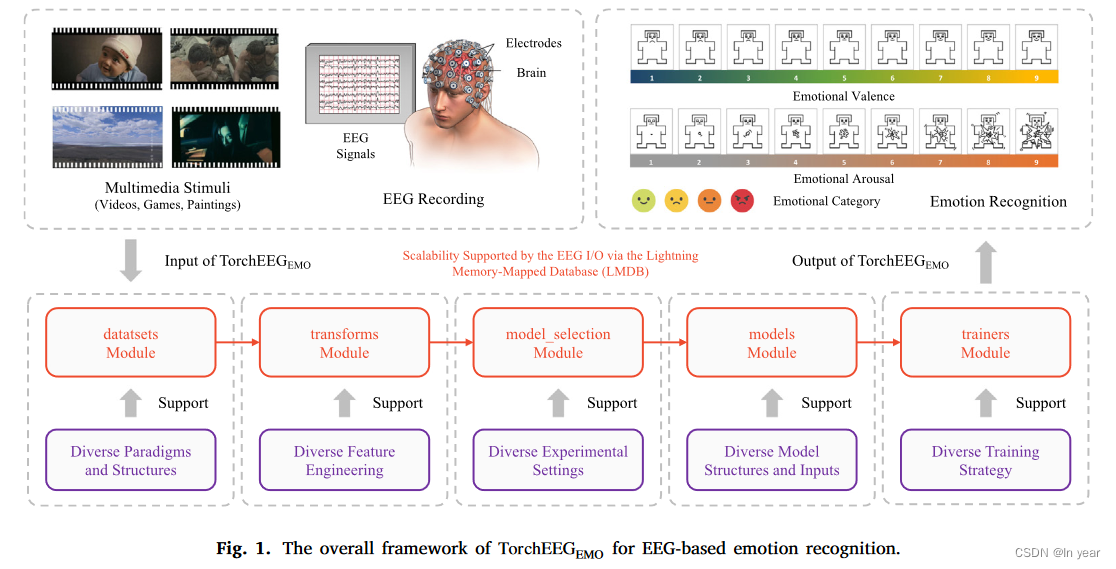
1.datasets模块
支持的数据集:DEAP、DREAMER、SEED、MAHNOB、AMIGOS、MPED。数据集模块可以帮助分析这些数据集的文件结构,加载记录的脑电信号,并将其与描述信息进行匹配,以便于编制索引。
为了提高识别效率并更早地识别新情绪,现有方法将脑电信号分成多个窗口。由于要求不同,相关时间窗口的长度也可能不同。在数据集模块中,建议根据配置将试验脑电信号分割成指定长度,其中包括窗口长度和相邻窗口重叠的设置。然后将描述性信息与时间窗口对齐,提供刺激情绪、试验信息、会话详情、受试者描述和刺激多媒体。情绪识别的最佳窗口长度为12秒,使用1-2秒长的无重叠窗口。
2.transforms模块
利用时域、频域技术,提供适合脑电信号的各种转换。这些转换根据其作用分为四种类型:预处理、特征提取、数据转换和数据增强。
1.预处理转换采用信号处理技术,以提高脑电数据的信噪比。
2.特征提取转换遵循相关工作,从原始信号中提取低维但具有区分性的特征。
3.数据转换将隐蔽的脑电信号转换为适应深度学习模型的表示形式,如张量格式或图格式。
4.数据增强变换旨在利用几何变换等技术增加数据的多样性。
我们发现,在训练阶段,深度学习模型通常会针对多个epoch进行优化。每个脑电信号样本都在一个epoch中使用,因此在整个训练阶段会被多次使用。每次使用脑电信号样本时,都会进行变换。变换在不同的epoch中重复执行,导致不必要的时间计算。
因此,我们提出了离线变换。这些离线变换可在每个epoch产生一致的结果,例如数据预处理(下采样等)和特征选择(差分熵、功率谱密度等)。我们在训练阶段之前进行这些处理,并将处理结果缓存在建议的以时间窗口为中心的脑电图输入/输出中。在每个epoch中,当样本被使用时,可以访问缓存的结果,从而避免重新执行变换。通过分离离线变换和在线变换,并缓存离线变换的结果,我们可以跳过重复计算,而选择缓存命中,从而解决了重复计算的问题,提高了系统效率。
3.model_selection模块
将数据集拆分成训练集、验证集和测试集的方法。最直接的方法是K折交叉验证,即随机将数据集分成K个子集。每个子集作为K个实验中的一个测试集,而其余子集构成训练集。模型的性能报告为K个测试集的平均结果。
然而,随着相关研究的发展,一些研究认为,由于情绪是大脑中连续的认知过程之一,单个试验中的数据段之间存在高度相关性。在对数据进行训练-测试分割之前,将数据段在试验之间随机洗牌,可能会导致相邻的数据段出现在训练和测试数据中,从而导致高的分类结果。当高度相关的数据段在真实世界情况下从未被模型观察到时,准确性会下降(Ding, Robinson, Zhang, Zeng, & Guan,2022)。TorchEEGEMO提供了KFoldGroupbyTrial和KFoldCrossTrial。前者将每个试验分成𝑘个周期;每个周期在𝑘个实验中作为测试集,而剩余的子集组成训练集。后者考虑了试验间的差异,并将每个受试者的试验分成𝑘折,只在训练集中包括特定试验的EEG样本。TorchEEGEMO 进一步提供了 LeaveOneSubjectOut 和 KFoldCrossSubject。KFoldCrossSubject 将受试者分成 k 组,测试集由一组受试者的脑电图样本组成,训练集仅由 k - 1 组样本组成。LeaveOneSubjectOut 是一种特殊情况,其中 k 等于受试者总数。
4.models模块
提供了各种深度学习算法,专为基于脑电图的情感识别而设计。包括:卷积神经网络、循环神经网络、图神经网络。还进一步采用了自然语言处理和计算机视觉领域最先进的深度学习模型,如Transformers和Generative,以建立一个强大的基线。
使用Transformer适应EEG信号,将EEG信号视为来自不同电极的一系列信号段,并利用多头自注意力机制来分析这些信号段标记。
5.trainers 模块
提供了多种训练算法来优化模型的可学习参数。通过域适应算法来解决跨受试者问题。这些算法利用来自已知受试者的脑电图样本作为源域,利用来自未知受试者的样本作为目标域进行测试。通过设计特定的损失函数和训练策略,它们优化模型以提取领域不变特征或从源域向目标域转移知识。在这种情况下,我们为基于脑电图的情绪识别系统调整了通用的跨领域训练器。
(四)Time window-centric EEG input/output techniques
引入 了一个统一的输入和输出(IO)模块,该模块使用CSV文件和高效的Lightning内存映射数据库(LMDB)来存储EEG时间窗口。具体来说,IO模块根据用户配置对数据集中的原始脑电图记录进行分割,并将这些脑电图时间窗口存储在LMDB中。每个脑电图时间窗口的数据库索引和相关元数据(如:受试者索引和试验索引)被组织并存储在CSV文件中。
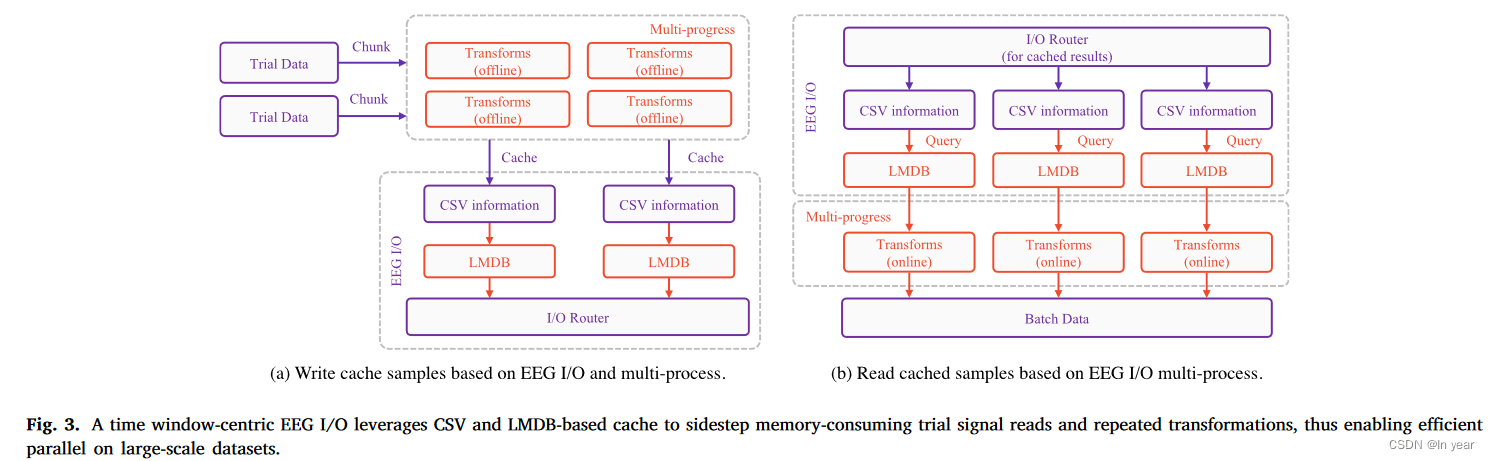
在数据集初始化阶段,创建了多个EEG IO。每个进程都被分配执行离线转换,并随后将中间结果写入负责的EEG IO,将元数据存储在相关的CSV文件中,并将脑电信号保存到LMDB中。然后,这些EEG IO 的路径被注册到IO路由器中。在数据集初始化之后,IO路由器负责管理所有EEG IO的CSV文件。通过这种方式,多个EEG IO对用户来说变得透明,使用户能够将其视为单一的、一致的数据集。在访问脑电时间窗口时,IO路由器从多个EEG IO中识别出适当的路径,然后从CSV中检索元数据,并从LMDB中提取处理过的脑电信号。然后,不同脑电时间窗口的索引和在线转换被并行执行。
这些技术允许对感兴趣的脑电图时间窗口进行索引,而感兴趣的窗口之外的脑电图记录不会加载到内存中,从而减少内存使用。多进程转换进一步减少了I/O系统中写入和读取所需的时间,进一步提高了系统的效率。
(五)基准测试结果
1.datasets模块上的基准测试结果
对于每个数据集,我们使用非重叠滑动窗口将每个试验中的脑电图信号划分为脑电图样本段,分别应用一秒的时间窗口和两秒的时间窗口。接下来,我们使用数据集中的价分数注释将样本标记为高/低类别。特别是,SEED数据集提供了正面、中性和负面的三类标签,我们制定了三类分类。SEED-IV数据集提供中性、悲伤、恐惧和快乐的情绪,我们制定了四类分类。最后,我们使用 KFoldGroupbyTrial 对 EEG 样本进行 5 倍交叉验证,并报告模型的平均精度和测试数据集上的标准差。
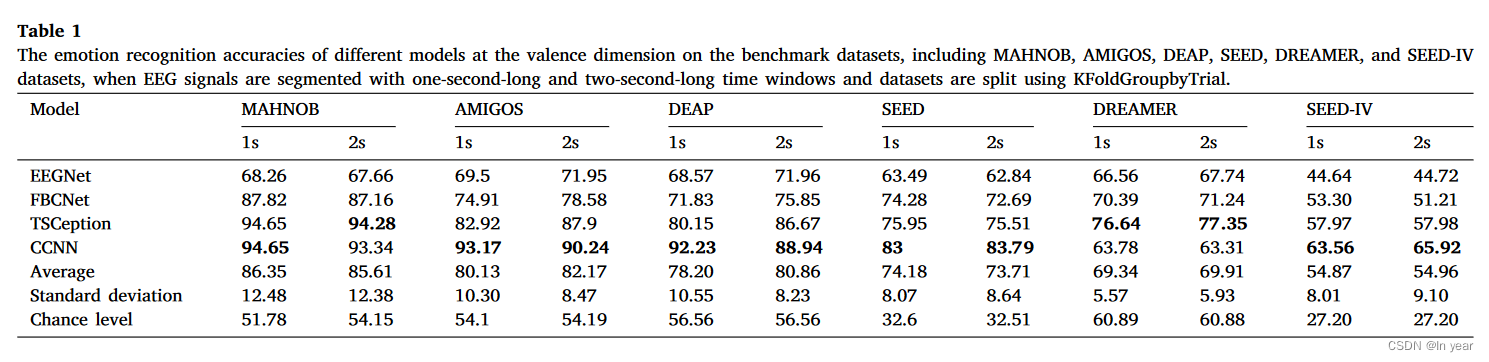
如表 1 所示,数据集按准确度从高到低的顺序排列如下:MAHNOB、AMIGOS、DEAP、SEED、DREAMER 和 SEED-IV。具体来说,在MAHNOB数据集上,平均准确率超过其他数据集,平均准确率超过85%。SEED-IV数据集的平均准确率最低,达到不到60%的准确率。这表明 SEED-IV 数据集对情绪识别提出了挑战,因为 SEED-IV 是一个四类分类任务。
我们还可以观察到,没有适合所有情况的通用窗口长度;最佳窗口长度因数据集和使用的模型而异。根据平均性能,两秒长的窗口在 AMIGOS、DEAP、DREAMER 和 SEED-IV 数据集中表现良好。相比之下,对于 MAHNOB 和 SEED 数据集,一秒长的窗口更有效。但是,我们没有观察到超过 7% 的性能差距,这表明窗口长度不是性能的主要因素。因此,我们建议从一秒长的窗口开始用于实时应用程序,并进行试验以找到最佳窗口长度。
一些相关工作还讨论了基于脑电的情绪识别数据集中存在的类别不平衡问题。因此,我们计算了具有不同窗口长度设置的数据集的机会水平准确度,以说明数据集的不平衡性,即不考虑脑电信号而猜测第一个类别的情况下。在这里,SEED数据集提出了一个三类分类问题,平衡数据集的机会水平准确度接近33.33%。SEED-IV数据集是一个四类分类问题,平衡数据集的机会水平准确度接近25.00%,而其他数据集则呈现了二类分类问题;因此,平衡数据集的机会水平准确度为50%。从表1中我们可以发现,基准数据集的机会水平表现与其相应的平衡情况下的机会水平有所不同。这表明数据不平衡问题确实存在,并且我们观察到这种现象在DREAMER(50%,超过10%)和DEAP(50%,超过6%)中更为严重。
2.transforms模块上的基准测试结果
在本小节中,我们将讨论不同数据预处理对模型性能的影响。在这里,我们选择基于特征的模型CCNN来评估特征工程技术对模型性能的影响。具体来说,为了保持与上述实验一致的其他设置,我们使用平均绝对偏差 (MAD)、Hjorth 迁移率 (HM)、峰度、偏度、去趋势波动分析 (DFA)、功率谱密度 (PSD)、近似熵 (AE) 和微分熵 (DE) 分别从 EEG 样本段中提取特征,并去除基线信号的分量。除了 MAD 和 DE 之外,我们在特征提取后使用最大最小归一化来防止参数达到极值。
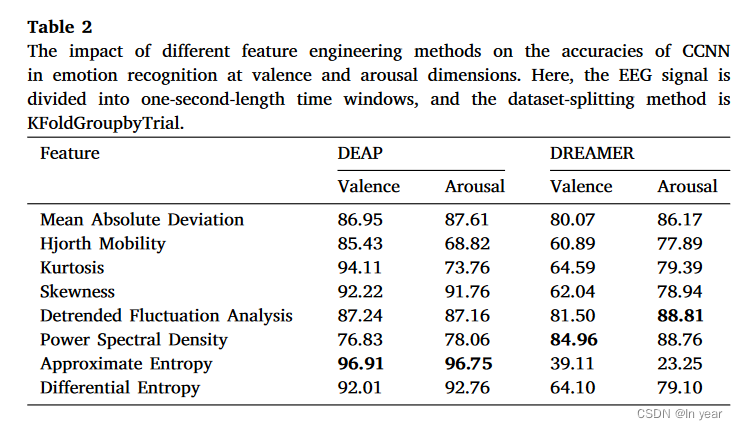
如表2所示,PSD在DREAMER数据集上表现最佳。这可能是由于 DREAMER 数据集的 EEG 信号中的信噪比较低,其中大多数特征提取方法的平均性能较低。频域方法测量感兴趣成分的频率,并忽略与情绪无关的频段的影响(Wang & Wang,2021),从而改善了低信噪比并实现了更好的性能。DEAP 数据集中的 EEG 信号表现出高度非线性和非平稳的行为。在该数据集中,AE和DE表现出比频域特征更好的性能,表明基于熵的特征在非线性动力学方面取得了进步(Yu&Wang,2022)。实验结果还表明,DFA在低信噪比DREAMER数据集上表现良好,该数据集在从EEG数据中去除伪影方面显示出有希望的结果(Yu&Wang,2022)。
3.model_selection模块的基准测试结果
在本小节中,我们进一步评估了数据集拆分策略对情绪识别性能的影响。详细地,我们评估了CCNN模型在基准数据集上的性能,包括DEAP、DREAMER、SEED、AMIGOS、MAHNOB和MPED。我们使用一秒长度的非重叠滑动窗口将每个实验中的脑电图信号分成脑电图样本的片段。然后,我们从脑电图样本片段中提取DE特征,并去除基线信号的分量。最后,我们应用不同的交叉验证策略,并报告了模型在测试集上的平均准确率。对于 KFold、KFoldGroupbyTrial、KFoldCrossTrial,我们使用了 5 倍交叉验证。对于 KFold,我们随机洗牌 EEG 样本,对于 KFoldGroupbyTrial 和 KFoldCrossTrial,我们没有随机洗牌样本,这意味着 EEG 样本的连续序列分别用作训练/测试数据集。
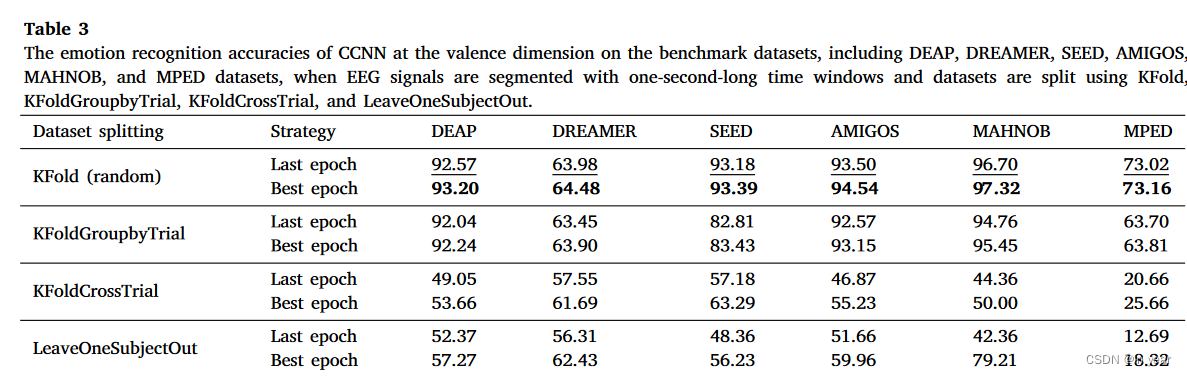
值得注意的是,部分相关研究报告了模型在最后一个训练周期上的性能;而其他则报告了在测试数据集上使用最佳参数时的模型性能。以下我们分别称之为最后周期策略和最佳周期策略。在本文中,我们尝试了这两种策略。如表3所示,模型在KFold(随机)上的表现更佳。这是因为KFold(随机)从数据集中随机采样脑电信号作为训练样本。因此,训练样本在受试者、实验和时间段之间均匀分布。这样,训练数据集和测试数据集之间的域差异较小,导致情绪识别相对容易。相反,KFoldGroupbyTrial策略只覆盖训练样本中的部分时间段,模拟部分时间段未知时的情绪识别。因此,测试数据集和训练数据集之间存在域差异,增加了分类难度。类似地,KFoldCrossTrial和LeaveOneSubjectOut的设置进一步模拟了训练集中部分试验/受试者未知的情况,进一步增加了准确分类的挑战。同时,我们还可以发现,在DREAMER、SEED、MAHNOB和MPED数据集上,KFoldCrossTrial设置下的模型性能(最后周期策略)高于LeaveOneSubjectOut,在DEAP和AMIGOS数据集上则相反。这表明,在DREAMER、SEED和MAHNOB数据集上,试验之间的分布差异大于受试者之间的分布差异,而在DEAP和AMIGOS数据集上则相反。
最后,我们观察了最后epoch策略和最佳epoch策略在测试数据集上的性能差异。可以发现,无论数据集和数据集分割设置如何,两种策略之间的性能差异均不超过1%。特别是在一些极端情况下,我们发现受随机初始化的影响,最后epoch策略在某些数据集和数据分割策略中可能超过了最佳epoch策略。这种现象可能表明,模型在多次训练轮次后能够稳定收敛到理论上限附近,表明了模型设计和训练的稳定性。
4.models模块上的基准测试结果
在本小节中,我们将对最近的模型进行进一步的实验。对于判别模型,我们验证了基于图卷积的模型(DGCNN、RGNN 和 LGGNet)和基于 Transformer 的模型(Transformer、ViT、SimpleVit 和 ArjunViT)的性能。为了证明超参数在模型中的影响,我们通过配置不同的隐藏层大小并在 5 倍 KFoldGroupbyTrial 交叉验证下记录模型性能,在模型架构中试验了不同的隐藏层大小。
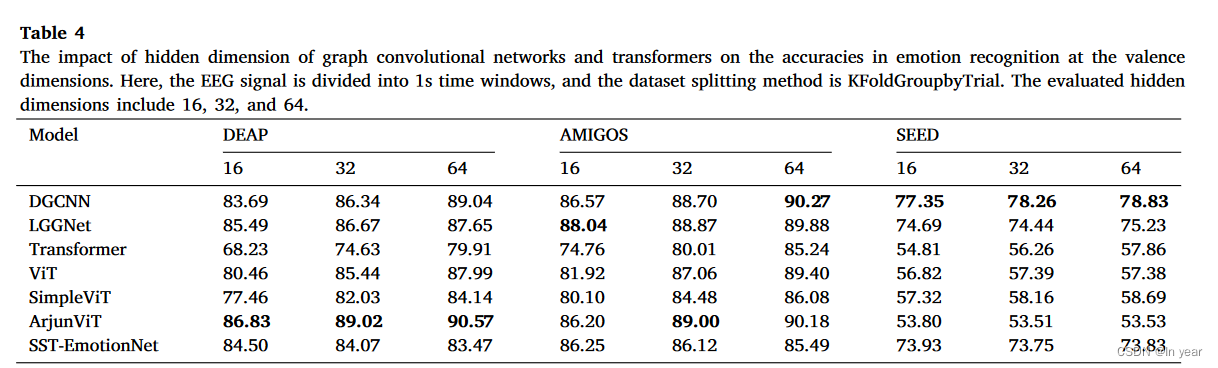
如表4所示,图卷积网络在DEAP、AMIGOS和SEED数据集上实现了最佳性能。这可能是因为图卷积网络比transformer更好地模拟了电极和脑电图信号的大脑区域之间的潜在结构模式,从而提供了有效的感应偏差来对情绪状态进行分类。同时,一些基于Transformer的方法在DEAP和AMIGOS数据集上表现出良好的性能;但是,它们在 SEED 数据集上的表现不能优于基于 GNN 的方法。这可能是由于 transformer 在 SEED 数据集上遇到的过拟合问题。此外,我们发现,对于大多数数据集和模型,随着隐藏层大小从16个增加到64个,模型的性能逐渐提高,如表4所示。这种现象可能表明,广泛的自由参数有利于模型拟合复杂的脑电图信号分布。
然后,我们在生成模型上进行实验。在这里,我们使用一秒长度的非重叠滑动窗口将每个试验中的脑电图信号划分为脑电图样本的片段。然后,我们从脑电图样本中提取DE特征,并去除基线信号的分量。接下来,我们训练生成模型,以从接近真实脑电图样本分布的不同电极生成脑电图信号的DE特征。在训练生成模型后,为了测量生成模型的性能,我们使用核最大平均差异(MMD)(Gretton,Borgwardt,Rasch,Schölkopf和Smola,2006),初始评分(IS)(Salimans等人,2016)和FID(Fréchet初始距离)(Heusel,Ramsauer,Unterthiner,Nessler和Hochreiter,2017)来测量生成的脑电图信号和真实脑电信号的分布之间的差异。 以及生成的脑电图信号的多样性。在这里,我们对 EEG 数据集使用 5 倍 KFoldGroupbyTrial 交叉验证,并报告了不同生成模型的平均内核 MMD、IS 和 FID。
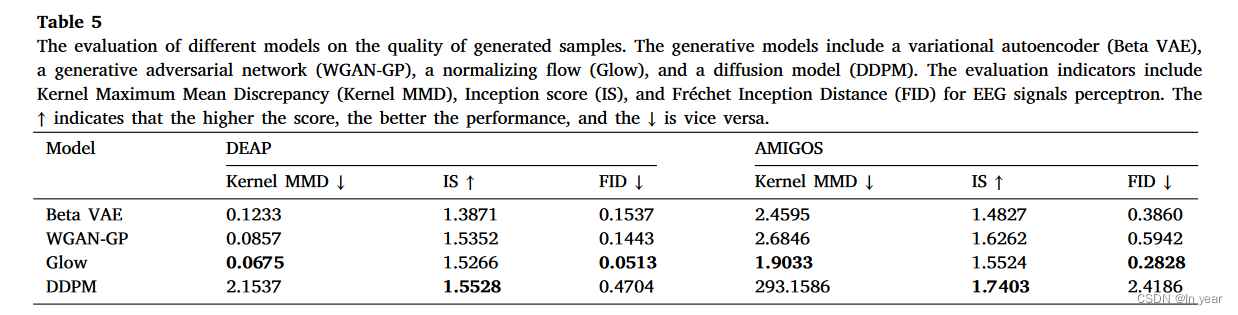
如表 5 所示,在 DEAP 和 AMIGOS 数据集上,Glow 优于内核 MMD 和 FID 最低的其他生成模型。较低的FID表示Glow生成的样本分布与真实样本的分布一致。DDPM实现了最高的IS,表明DDPM可以产生许多不同的脑电信号,而其在内核MMD和FID上的性能相对较差。我们认为这是由于电极数量少和脑电图信号的空间分辨率低。众所周知,DDPM中的UNet架构是为生成具有高空间分辨率的图像而设计的,可能不适合具有低空间分辨率的EEG信号。
5.trainers模块的基准测试结果
在本小节中,我们首先进行敏感性实验,以探索超参数在训练深度学习模型时的影响。在 DEAP 数据集上进行实验,以评估经过训练的 CCNN 在不同超参数组合下预测情绪效价和唤醒的性能。在实验中,将脑电信号划分为一秒长的时间窗口,并使用 KFoldGroupbyTrial 对数据集进行分区。我们采用近似熵作为输入特征。我们报告了学习率为 [0.001, 0.0001, 0.00001]、权重衰减为 [0.001, 0.0001, 0.00001] 和辍学率为 [0.3, 0.4, 0.5] 下的分类准确性。
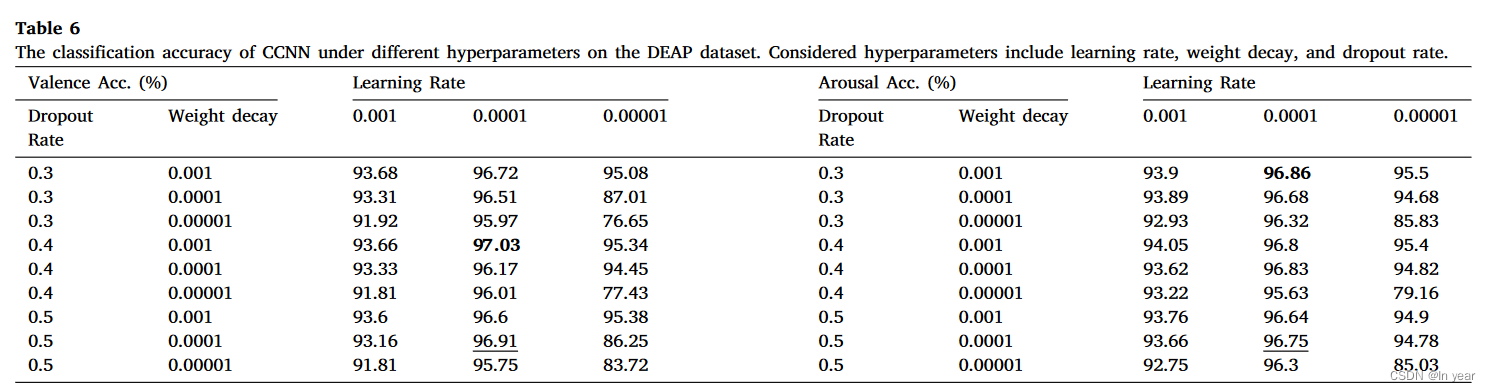
如表6所示,我们使用粗体来表示最佳性能,使用下划线来表示默认设置下的性能。我们发现,用于分类情绪和唤醒的最佳性能对应不同的超参数,表明没有一种适合所有情况的超参数组合。我们还观察到最佳超参数和默认超参数之间的性能余量约为0.1%,表明默认值是一个合理的起点。超参数过大或过小可能导致性能下降超过10%,突显了超参数对性能的重大影响。
然后,我们在基准数据集 DEAP 和 SEED 上进行实验,以评估跨学科情绪识别设置中的跨领域训练器。我们使用一秒长度的非重叠滑动窗口将每个实验中的脑电图信号划分为脑电图样本段,然后应用 LeaveOneSubjectOut 交叉验证策略来报告最终性能。
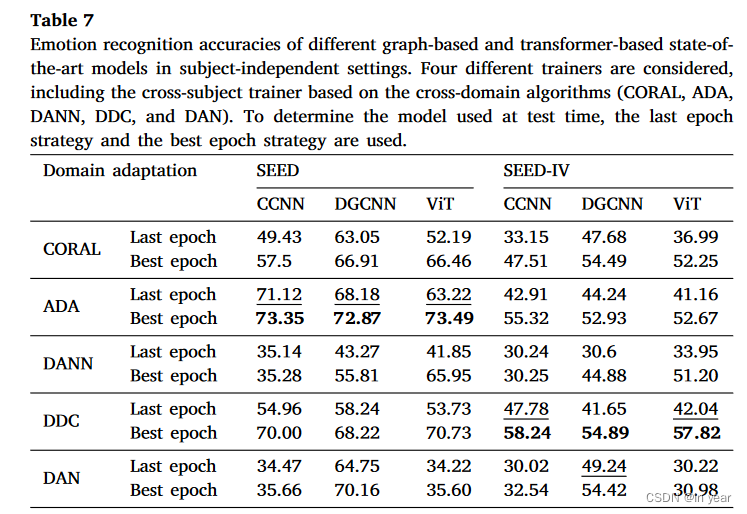
如表 7 所示,我们发现 ADATrainer 在 SEED 数据集上取得了更好的性能。这是因为 ADATrainer 实现了条件分布自适应算法。这种算法旨在最小化条件分布 P (
X
S
,
Y
S
X_S , Y_S
XS,YS) 和 P (
X
T
,
Y
S
X_T , Y_S
XT,YS) 之间的距离,其中 X 表示 EEG 信号,Y 表示标签。它可以对齐由标签调节的脑电信号,从而更好地区分目标域中的不同类别。在SEED-IV数据集上,有更多的情感类别。源域的分类准确率不超过70%。在这种场景下,分类损失和条件分布适应损失相互竞争,导致分类损失的优化效果不佳。一个简单的领域适应训练器 DDCTrainer 带来了最佳性能。
我们进一步进行了可视化实验,以深入了解跨域算法优化的CCNN的决策基础。在 SEED 数据集中,每个受试者在不同日期参加了三个会话的试验。对于每个会话,我们使用 ADATrainer 对三个受试者进行采样作为测试集,其余受试者作为训练集。随后,我们在 3 个测试对象上可视化优化的 CCNN 的最后一个卷积层输出的特征,简化为二维平面。
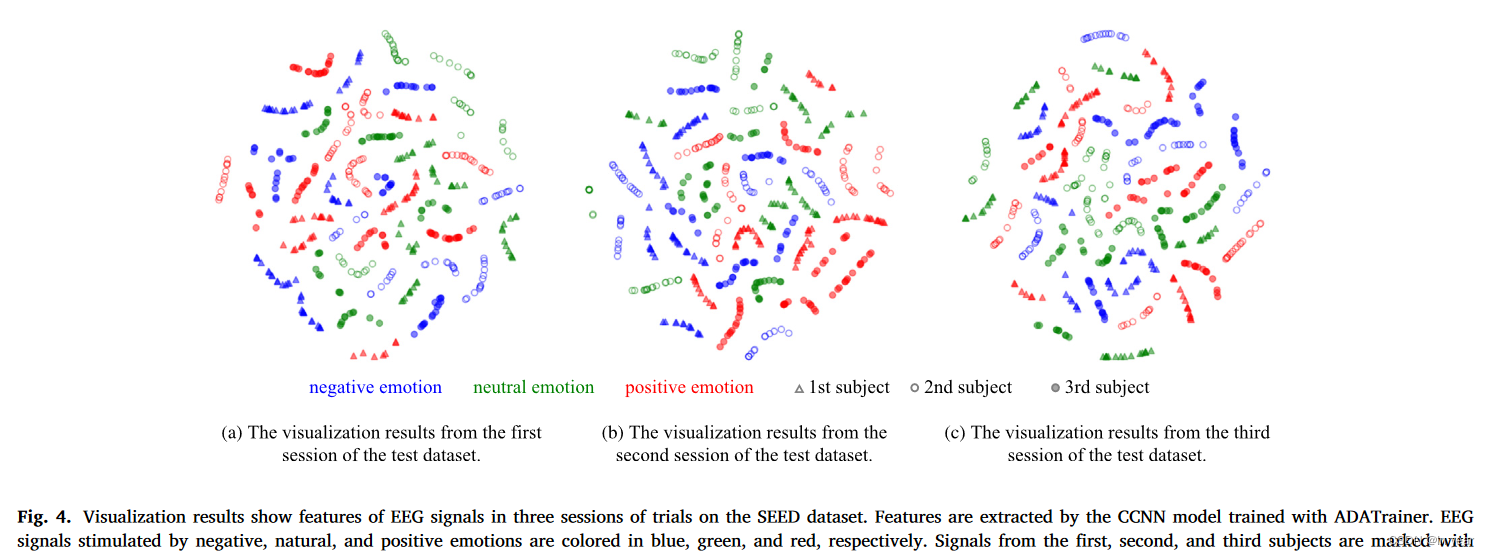
如图4所示,散点的颜色代表情感类别,不同的形状代表不同的主体。我们观察到相同颜色的点聚集在一起,而不同颜色的点彼此相距很远。结果表明,优化后的CCNN可以提取出不同的情感特征进行分类,其中同一情感类别的特征相似,不同类别的特征不同。我们还可以找到相同颜色但不同形状聚集在一起的点,例如图4(b)中左侧的蓝色点和右侧的红色点。这意味着不同主题中同一情绪类别的共同特征被捕获,从而能够在跨主题场景中进行正确的情绪分类。
6.TorchEEGEMO I/O 的基准测试结果
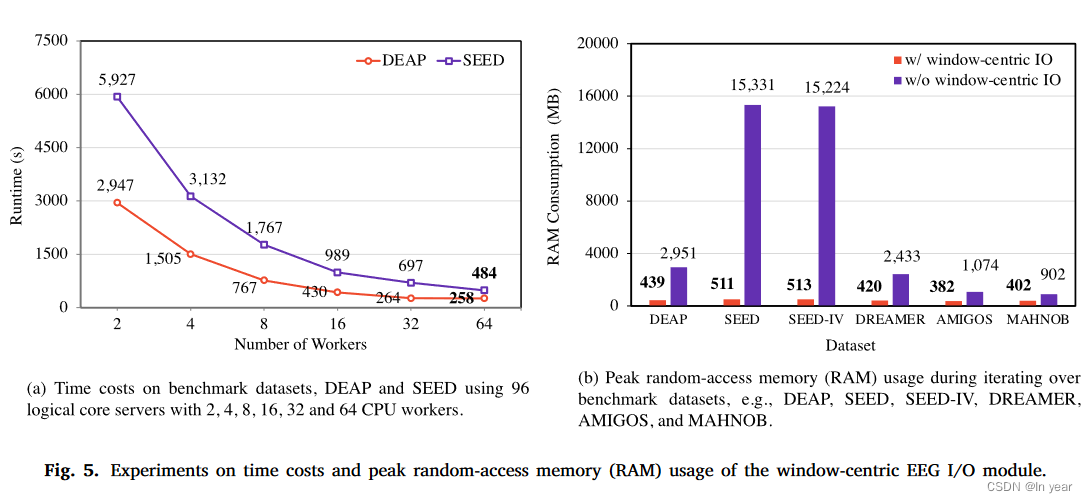
在本节中,我们进行了实验,以强调所提出的以窗口为中心的输入/输出技术的有效性。我们首先演示了以窗口为中心的 EEG I/O 系统所降低的时间成本。在实验中,我们使用 BandDif ferentialEntropy 和 ToGrid 作为变换,即给定一个 EEG 信号样本,我们计算四个子带的微分熵,然后将每个电极的熵映射到网格。我们使用 96 个逻辑核心服务器和 2、4、8、16、32 和 64 个 CPU 工作线程,在基准数据集 DEAP 和 SEED 上记录时间成本。如图 5(a) 所示,由于 SEED 数据集的脑电图样本量较大,因此比 DEAP 数据集需要更长的时间。对于 SEED 和 DEAP,随着 CPU 工作线程的数量呈指数级增长,处理时间呈指数级减少。这种现象显示了以时间窗口为中心的脑电图 I/O 的有效性,并且开销最小。
然后,我们展示了以窗口为中心的 EEG I/O 带来的内存减少。我们迭代各种基准数据集,无论是否使用我们提出的以窗口为中心的 IO,并使用“mprof”来跟踪程序执行期间的峰值内存使用情况。如图5(b)所示,在所有数据集中,采用所提出的以窗口为中心的输入/输出系统可以降低内存消耗。这种效率源于这样一个事实,即如果没有我们的系统,脑电图信号是通过试验记录来组织的。为了创建训练样本,将脑电图记录加载到内存中以分割脑电信号的窗口,例如一秒长的窗口。使用我们以窗口为中心的 IO,EEG 记录在 LMDB 的窗口中组织,并且仅读取感兴趣的索引窗口。值得注意的是,在具有大量长记录的基准数据集上,例如 SEED 和 SEED-IV,内存节省更为明显。
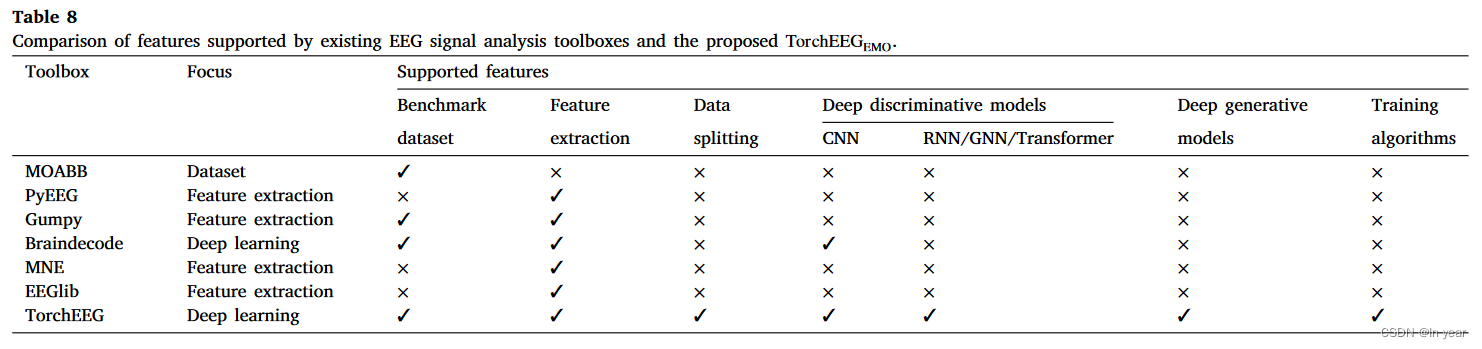
如表 8 所示,大多数现有工具箱都专注于提供信号处理和提取判别特征,例如 MNE、EEGlib、PyEEG 和 Gumpy。这些功能有助于使用神经科学见解进行初步的脑电图分析。然而,他们缺乏对深度学习算法的支持,而深度学习算法代表了当前的状态。与TorchEEGEMO集成后,研究人员可以进一步受益于深度学习算法的最新进展。
MOABB 和 Braindecode 提供了广泛的基准数据集,广泛用于进行运动意象、睡眠阶段检测等实验。据我们所知,目前还没有工具箱为基于脑电图的情绪识别提供内置的基准数据集,而 TorchEEGEMO 可以作为强大的补充,还为用户提供利用 MOABB 和 Braindecode 支持的数据集的接口。
与 TorchEEGEMO 最相似的工具箱是 Braindecode,它实现了用于运动意象和睡眠阶段检测的卷积神经网络,在社区中获得了广泛关注。然而,支持的模型并不是为基于脑电图的情绪识别量身定制的,RNN、GNN和Transformer等尖端发展,以及被证明有效的生成模型,尚未被包括在内。TorchEEGEMO填补了这一空白。
与其他工具箱不同,TorchEEGEMO 还提供标准的数据集拆分程序,用于划分训练样本,以训练具有不同目标的深度学习模型。据我们所知,TorchEEGEMO也是唯一提供训练策略(例如领域适应)的工具箱,以使用高级算法优化深度学习模型。
(七)总结和未来工作
总之,TorchEEGEMO是一个全面而高效的基于脑电图的情绪识别工具箱。它将基于脑电图的情绪识别工作流程分解为五个不同的模块,并为基准数据集(数据集模块)、转换工具(转换模块)、数据拆分策略(model_selection模块)、深度学习模型(模型模块)和训练算法(训练器模块)提供即插即用功能。通过集成以时间窗口为中心的脑电图输入/输出,TorchEEGEMO提高了基于脑电图的情绪识别的深度学习系统的效率。
数据集上的实验表明,不同数据集的性能各不相同。我们发现没有一个模型主导所有数据集,这表明选择合适的模型的重要性。最佳窗口长度可以进一步提高性能。变换模块上的实验揭示了特征提取对情感识别性能的影响。时域和频域特性都有其特定的应用场景。model_selection上的实验凸显了看不见的小径和受试者带来的挑战。这些模型模块在实验中被广泛研究,表明最先进的方法可以通过优化管道(例如特征工程)实现进一步的改进。简单而高效的CCNN仍然是一个强大的基准。经过调整的基于transformer的模型显示出优于GNN的性能。引入的生成模型在数据增强方面显示出巨大的潜力。训练器上的实验突出了各种领域适应算法的有效性。条件域自适应似乎对未来的研究很有希望,但简单而高效的传统方法在实际应用中仍然具有价值。
通过在多个数据集上的实验表明,模型的性能会因数据集的不同而有所变化。我们发现没有一个单一模型能够在所有数据集中都占据主导地位,这凸显了选择合适模型的重要性。最优窗口长度的选择能够进一步提升性能表现。在transforms模块的实验揭示了特征提取对情感识别性能的影响,时域特征和频域特征在各自特定的应用场景中都有其独特价值。模型选择模块的实验显示,未见过的试验样本和受试者给模型带来了挑战。针对模型模块的广泛研究表明,通过最优的流程设计,如特征工程优化,当前最先进的方法能够实现性能的进一步提升。其中,简单而高效的卷积循环神经网络(CCNN)仍然是一个有力的基准参照。经过调整的基于Transformer的模型在与图神经网络(GNNs)对比时展现出令人期待的性能。引入的生成模型在数据增强方面显示出巨大的潜力。训练器模块的实验突出了各种领域适应算法的有性。条件性领域适应法在未来研究中展现出前景,但同时,简单且高效的传统方法在实际应用中仍保持着其价值。
对于未来的工作,我们认为没有放之四海而皆准的解决方案;不同的研究成果有其自身的好处和合适的用例。因此,我们的目标是不断集成各种最先进的算法,并提供一个预训练的基础模型中心,作为各种研究目标和实际应用的起点。